Learn audio decoding and rendering with Cavern
Rendering object-based content
When an audio stream doesn't directly contain what each speaker should play, just where each sound is, we need to calculate which speakers should play which sound. This process is called rendering. When we want to virtually move a speaker, like playing back any content on arbitrary layouts with Cavern, it also requires rendering. It's exactly the same, we treat the source channels as objects that need to be placed in the user's space. Multiple renderers are used in practice, Cavern can even switch between them in real time if a layout change requires it.
Balance-based rendering
The industry standard method for finding which speakers should play a specific sound is the balance-based rendering technique. The basic theory is we need to find what speakers would create a bounding box around the object, and pan the volumes according to which speaker is closer to the object.
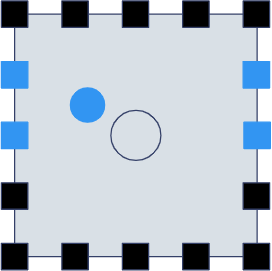
As seen on the picture, this requires the two sides of the room to have speakers at exactly the same locations. Thus, Cavern is only using this renderer when the layout is symmetric.
The image shows how a bounding box is found for a single layer: find the speakers on the sides that are just ahead/behind, and if we're near the front or rear wall, closer speakers to the left or the right of the object can be considered. Determining the volumes is easy: just check the ratio of the object's location between the left/right speaker pairs, and use that value. If it's closest to a speaker than the other, this multiplier should be 1, if it's halfway, then 0.5, and if the object is completely at the other side, it's weight becomes 0. We also take the square root of each multiplier to achieve constant power mixing, meaning the volume of the object will stay the same as it moves across channels. The same multiplication happens to the speakers in front of and behind the objects, these numbers get multiplied together. Then we take layers into consideration: the previous example was described for speakers located at the same level, but heights were not considered. We just find the layer directly above and below the speaker, and just do the same exact multiplication over the existing values we calculated. This makes it possible to have speaker layouts of more than 2 layers, even layers below the main channels.
Pros and cons
The main reason this renderer was chosen as a de facto standard is its ability to both allow objects being panned across the inside of the room, and provide close to the same experience to all seating positions. This is called an allocentric renderer, taking every listener in a large room into account. Other rendering methods can only achieve this through limitations or hacks. It's also very easy to implement, the code runs without any trigonometric calculations, we technically only need to calculate ratios of line lengths. The downside is being locked to symmetric layouts, which is not always convenient. Experiencing objects moving inside the room is also not given by the method itself, it requires very precise calibration, such as what Cavern QuickEQ can provide.
Distance-based rendering
The easiest way to create a renderer is to simply play the sound from all speakers, and set the volumes depending on object distance. If the object is at the speaker, make the volume maximum, and if it's at the exact opposite side of the room, make it silent. We don't need the square root trick now, as it only works when only two speakers account for one axis.

Because of this definition, we are free of any limitations, speakers can be placed anywhere. When the speakers are not placed symmetrically, this is the renderer Cavern falls back to, but only in the home, because of its downside:
This is only an advertisement and keeps Cavern free.
Pros and cons
Because each speaker plays every object to allow any layout, sitting close to any speaker will sound like everything is coming from there. Thus, this solution is only applicable when there is a relatively large distance between the seating positions and speakers. The mixing method is only applied in the industry where surrounds are really far away from listeners. In the cinema, these are the absolute largest rooms. The effect can be mitigated by raising the objects' distances (which are measured between 0 and 1) to relatively high powers like 8 or 16. This way the sounds get mixed close to the direction they arrive from, but this breaks in-room panning. This is what Cavern does to account for average sized rooms with uneven speaker placements.
Directional rendering
Moving on from the basic theory of distance-based rendering, to fix its shortcomings, we could just limit playback to the closest speakers, or the bounding two on a single layer. In full space, we find a bounding triangle of speakers, and pan accordingly.

Cavern is using this renderer for studios and theaters that are asymmetric, because in these environments, people can sit close to speakers. Because we limit playback to the closest speakers, in-room panning is generally disabled, and objects close to the center of the room might snap sides unexpectedly. To counter this, mixers must manually add a counter object to the opposite side with opposite volume to add a panning effect when needed. However, this is not recommended, as it introduces the downside of distance-based rendering.
Pros and cons
Works with any layout, even asymmetric ones, in any environment, but no in-room panning is possible, and workarounds are not recommended.